The formula describes an operation that is performed on each cell and which yields a number. When all the numbers are summed, the result is χ 2. Now, compute it for the six cells in the example: 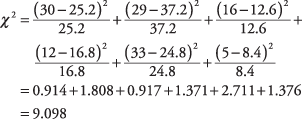
The larger χ 2, the more likely that the variables are related; note that the cells that contribute the most to the resulting statistic are those in which the expected count is very different from the actual count.
Chi‐square has a probability distribution, the critical values for which are listed in Table 4 in "Statistics Tables." As with the t‐distribution, χ 2 has a degrees‐of‐freedom parameter, the formula for which is
(number of rows – 1) × (number of columns – 1)
or in your example:
(2 – l) × (3 – 1) = 1 × 2 = 2
In Table 4 in "Statistics Tables," a chi‐square of 9.097 with two degrees of freedom falls between the commonly used significance levels of 0.05 and 0.01. If you had specified an alpha of 0.05 for the test, you could, therefore, reject the null hypothesis that gender and favorite commercial are independent. At a = 0.01, however, you could not reject the null hypothesis.
The χ 2 test does not allow you to conclude anything more specific than that there is some relationship in your sample between gender and commercial liked (at α = 0.05). Examining the observed versus expected counts in each cell might give you a clue as to the nature of the relationship and which levels of the variables are involved. For example, Commercial B appears to have been liked more by girls than boys. But χ 2tests only the very general null hypothesis that the two variables are independent.
Sometimes a chi‐square test of homogeneity of populations is used. It is very similar to the test for independence. In fact the mechanics of these tests are identical. The real difference is in the design of the study and the sampling method.